Ewpt Introduction
EWPT Introduction
- We need some informtion before begin web application security testing
- HTTP/HTTPS Protocol Basics
- Encoding
- Same Origin
- Cookies
- Session
- Web Application Proxies
HTTP Protocol Basics
- Hypertext Transfer Protocl (HTTP) is the basic protocol used for web browsing and for most other communication on the web.
- HTTP is client-server protocol used to transfer web pages and web application data. The client is ususalyy a web browser that starts a connection to a server web such as MS IIS or Apache HTTP Server.
- During an HTTP communication , the client and the server exchage messages. The client send
requeststo the server and get backresponses. The format of an HTTP message is:
HEADERS\r\n
\r\n
MESSAGE BODY\r\n
\r\n: same of hitting enter
HTTP Request

- Examine an HTTP request in detail. The following is the content of the request that we send when we open web browser and navigate to numanaytemiz.github.io
GET / HTTP/1.1
Host: numanaytemiz.github.io
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/115.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Encoding: gzip, deflate
Connection: keep-alive
- we see here
http request headers - REQUEST METHOD
GETis our requet type (also known as an HTTPVerb). GET is the default request type when we type a URL into the location bar of our web browser and hit Enter.- Other
VerbsarePOST, PUT,DELETE, OPTIONS, TRACE...
- PATH
/path is the file we are requesting. The home page of a website is always/. Other pages can be requested, such as :/downloads/index.php. Our request always refers to the root folder to specify the requested file (hence the leading/)
- PROTOCOL
HTTP/1.1is the HTTP protocol version that our browser wants to talk with. This basically informs the web server about which version of HTTP we would like to use in any further communication.
- HOST HEADER
Host:is the beginnig of HTTP request headers. HTTP headers have the following structure:Header-name:Header-Value- The
Hostheader allows a web server to host multiple websites at a singel IP address. Our browser is specifying in the Host header which website you are interested in.
- HOST VALUE
numanaytemiz.github.iois the Host Value. After each request header, we will find its corresponding value. In this case we want to reach the Host numanaytemiz.github.ioHost Value + Path = URLdefine we are requesting
- USER-AGENT
- The
User-Agentreveals your browser version, operating system and language to the remote web server. All browsers have their own user-agent identification string.
- The
- ACCEPT
- The Accept header is used by our browser to specify which document type is expected to be returned as a result of this request.
- ACCEPT-ENCODING
- The
Accept-Encodingis similar to Accept, but it is restricts the content codings that are acceptable in the response. Content codings are primary used to allow a document to be compressed or transformed without losing the identity of its media type and without loss of information.
- The
- CONNECTION
- With HTTP 1.1 we can keep our connection to the remote web server open for an unspecified amount of time using the value
keep-aliveThis indicates that all requests to the web server will continue to be sent through this connection without initiating a new connection every time (as in HTTP 1.0)
- With HTTP 1.1 we can keep our connection to the remote web server open for an unspecified amount of time using the value
HTTP Response

HTTP/2 200 OK
Date: Sun, 10 Sep 2023 10:12:01 GMT
Cache-Control: max-age=600
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Server: GitHub.com
Content-Length: 7145
<PAGE CONTENT>
- let us examine web server response
- In response to the HTTP request, the web server will respond with the requested resource, preceded by a bunch of new heders.
-
These new headers from the server will be used by your web browser to interpret the content contained in the Response content.
- STATUS LINE
- The first line of the response message is the Status-Line, consisting of the protocol version (HTTP 1.1) followed by a numeric status code (200) and it is relative textual meaning (OK).
- The more common status code are:
- 200 OK, the resource is found.
- 301 Moved Permanently, the requested resourse has been assigned a new permanent URI
- 302 Found, the resource is temporarily under another URI
- 403 Forbidden, the client does not have enough privileges and the server refuse to fulfill request.
- 404 Not Found, the server cannot find a resource matching the request
- 500 Internal Server Error, the server does not support the functionality required to fullfill the request.
- DATE
- Date represents the date and time at which the message was originated.
- Cache Header
- The Cache Headers allow the Browser and the Server to agree about caching rules. Cached contents save bandwith because they prevent our browser from re-requesting contents that have not changed when the same resource is to be used.
- Content-Type
- Content-Type lets the client know how to interpret the body of the message.
- Content-Encoding
- Content-Encoding extends Content-Type. In this case the message body is compressed with gzip.
- SERVER HEADER
- The Server header displays the web server banner. Apache and IIS are common web servers. Github uses a custom webserver banner: GitHub.com
- Content Length
- Content-Length indicates the length, in bytes, of the message body.
-
Content
- This is the actual content of the requested resource. The content can be an HTML page, a document, or even a binary file. The type of the content is , of course, contained in the Content-Type header.
- The best way to understand something is to play around with it a bit. Firefox (as well as other web browser) already have some features that allow us to inspect HTTP Headers on the fly.
- Once Firefox Starts, open the options menu and select More Tools > Web Developer Tools > Network to inspect http requests and responses

HTTPS
- HTTP content , as in every clear-text protocol, can be easily intercepted or mangled by an attacker on the way to its destination. Moreover, HTTP does not provide strong authentication between two communicating parties.
- we will see how to protect HTTP by means of an encrytion layer.
- HTTP Sercure (HTTPS) or HTTP over SSL/TLS is a method to run HTTP, which is a clear-text protocol, over SSL/TLS, a cryptographic protocol
- This layering technique provides confidentiality, integrity protection and authentication to the HTTP protocol.
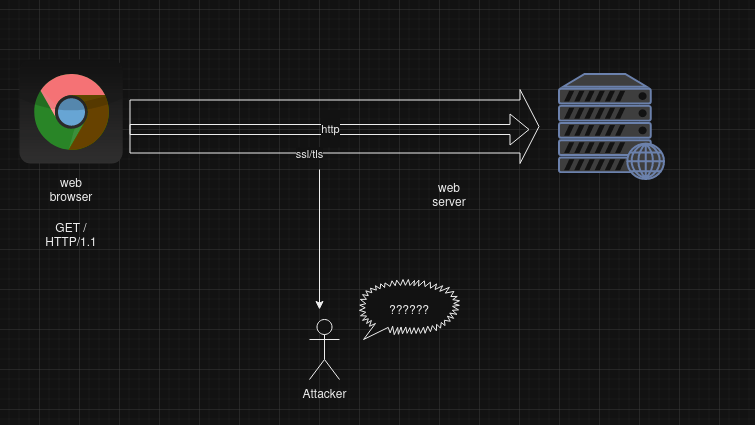
-
When using HTTPS
- An attacker on the path cannot sniff the application layer communication
- An attacker on the path cannot alter the application layer data
- The client can tell the real identity of the server and vice-versa
-
HTTPS does not PROTECT AGAINST WEB APPLICATION FLAWS!. The extra encriytion layer just protects data exchange between the client and the server. It does not protect from an attack against application itself. Attacks such as XSS and SQL Injectons will still work.
ENCODING
- Information encoding is a critical component of information technology.Its main function is to represent the low-level mapping of the information being handled.
- The encoding process, often invisible to end users, occurs each time an application needs to be elaborate on any data. Web applications are not excluded from this. Like many other applications, they continuously process thousands of pieces of informaion even for simple requests.
-
Understanding encoding schemes used by a web application can give you a big advantage during the detection and exploitation of a vulnerability.
-
CHARSET
- Internet users, via their browsers, request billions of pages everyday. All of the content of these pages are displayed according to a charset.But What is charset?
- Charset contains a set of characters, they represent the set of all symbols that the end user can display in their browser window. In technically, a charset consists of pairs of symbols and code points.
- The sysmbol is what the user reads, as he sees it on the screen. The code point is a numeric index, used to distinguish, the symbol within a charset. A sysbol can be shown only if it exists in the charset.
-
Example of charsets are: ASCII, Unicode, Latin-1 and so on
-
ASCII CHARSET
- The ASCII (American Standart Code for Information Interchange) charset contains a small set of symbols. Originally it was 128 only, but now it is usually defined with its extended version for a total of 255. It is old and it was designed to support only US symbols.For example ASCII cannot be used to display Chinese symbols amnong many others.
- Here is some exaple
CODE HEX SYMBOL 65 41 A 66 42 B 67 43 C 68 44 D 69 45 E 70 46 F 71 47 G 72 48 H - UNICODE
- UNICODE (Universal Character Set) is the character encoding standart created to enable people around world to use computers in any language. It supports all the world’s writing systems.
- HTML Encoding
- Even in HTML , it is important to consider the information integrity of the URL’s, and ensure that user agents display data correctly.
- There are two main issues to addres: inform the user agent on which cracter encoding is going to be used in the document, and the preserve the real meaning of some charcters that have specal significance.
- According to the HTTP 1.1 RFC , documnets transmitted via HTTP can send a charset parameter in the header to specify the charset encoding of the document sent; this is the HTTP header
Content-Type - HTML4 :
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1"> - HTML5:
<meta charset="UTF-8"> - If you intentionally set an incorrect charset, your browser may not display some symbols correctly.
- Although the primary purpose of HTML entites is not really to be a security feature, its use can limit most client side attacks
- URL Encoding
- As stated in the RFC 3986 , URLs sent over the internet must contains characetrs in the range of the US-ASCII code character set. If unsafe characters are present in the URL, encoding them is required. This encoding is important because it limits the characters to be used in a URL to a subset of specific characters.
- Unreversed Chars: [a-zA-z][0-9][-._~]
- Reversed Chars (they have a specific purpose): :/?#[]@!$&”()+,;=%
- Other characters are encoded by the use of a percent char (%) plus two hexadecimal digits. Reversed chars must be encoded when they have no special role in the url. What follows is a list of common encoded characters
- As stated in the RFC 3986 , URLs sent over the internet must contains characetrs in the range of the US-ASCII code character set. If unsafe characters are present in the URL, encoding them is required. This encoding is important because it limits the characters to be used in a URL to a subset of specific characters.
Character Purpose in URL Encoding # Seperate Anchros %23 ? Seperate query string %3F & Seperate query elemetns %26 + indicate a space %2B - When we visit a site , url-encoding is performed automatically by our browser. This happens automatically behind in the scenes in our browser while we surf.
-
Although it appears to be a security feature, URL-encoding is not. It is only a method used to send data accroos the Internet but it can lower the attack surface in some cases
- Base 64 Encoding
- Base64 is a binary-to-text encoding schema used to convert binary files and send them over internet. For example email protocol makes massive use of this encoding to attach files to messages.
- The html language permits the inclusion of some resources by using this encoding. For example, an image can be included in a page by inserting its binary content that has been converted to base64
- The alphabet of the base64 encoding scheme is composed of digits [0-9] and latin letters, bothe upper and lowe case [a-zA-Z], for a total of 62 values. To complete character set to 64 there are the plus (+) and slash (/) characters. Different implementations however, may use other values for the latest two characters and the one used for padding(=)
- The following code will show an image in a web document. The server will send this image without the needed to read it from another source like file system.

- In fact , remember that any web designer or developer could easily create their own encoding schema
SAME ORİGİN POLİCY
- One of the most important and critical points ow web application security is same origin policy.
- Same origin policy is a browser security feature.
- This policy prevents a script or a document from getting or setting another document that comes from a differnt origin.
- CSS stylesheets , images and scripts are loaded by the browser without consulting the policy.
- Same Origin Policy (SOP) is consulted when cross-site HTTP requests are initiated from within client side scripts (IE:javascript) or when an ajax request is run
- Origin Definitiaon
- Origin = Protocol + Host + Port

http://google.comandhttps://google.comis different origin because of protocol portion is different.-
Some SOP examples applied to the followind address : http://numanaytemiz.github.io/index.html
URL SOP Reason https://numanaytemiz.github.io/index.html Different Origin Different Protocol http://test.numanaytemiz.github.io/index.html Different Origin Different host http://numanaytemiz.github.io:8443/index.html Different Origin Different Port http://numanaytemiz.github.io/page.html Different Origin Same Protocol, host and port - What does SOP Protect From ?
- Suppose that we are logged in to our bank site and suppose our friend invites us to visit his new website which is malicious. As a general rule SOP prevents javascript or ajax , running on a given origin, from interacting with a document from a different origin. The primary purpose of SOP is to isolate requests coming from different origin
-
What would it happen if SOP did not exist?
- Our evil friend could build a crafted page, instigate you to visit it, and once visited by you , access some personal information from our bank account. As we can see without SOP you could not suft the Internet
- Here is Same Origin Policy Explanation in Labs
-
There are several exceptions to SOP restrictions:
- window.location
- document.domain
- Cross windows messaging
- Cross origin resource sharing (CORS)
Cookies
- HTTP is a stateless protocol. This measns that a website cannot retain the state of your visit between different HTTP requests without mechanisms such as as sessions or cookies. Each visit without a session or a cookie looks like a new user to a server and a browser.
- To overcome this limitation, in 1994 sessions and cookies were intended. Netscape , a leading company at that time, invented cookies to make HTTP stateful.
- Cookies are just textual information installed by a website into the “cookie jar” of the web browser. the cookie jar is the storage space where a web browser stores the cookies.
- They are fragments of text containing variables in the form of name=value.
-
A server can set a cookie via the Set-Cookie HTTP header. A cookie has a predefined format. It contains the followinf fields
- Domain
- Expires
- path
- Content
- http only flag
- secure flag
- Cookies Domain Field :
- A website only sets a cookie for its domain. (e.g. google.com sets a cookie for the domain google.com or .google.com)
- This means that the browser will install the cookie in the cookie jar and will send this cookie for any subsequent requests to :
- google.com
- www.google.com
- maps.google.com
- The scope of this cookie will be *.google.com
- Domain A cannot set a cookie for domain B.
- The browser will sends A’s cookie in accordance with the above domain scope (to A and all of its subdomains,) including the path and the expiration date.
- There are two important considerations about the domain fields.
- a leading “.”, if present, is ignored
- If the server does not specify the domain attribute, the browser will automatically set the domain as the server domain and set the cookie host-only flag. This means that the cookie will be sent only to that precise hostname.
- This means that the browser will install the cookie in the cookie jar and will send this cookie for any subsequent requests to :
- A website only sets a cookie for its domain. (e.g. google.com sets a cookie for the domain google.com or .google.com)
- Expires Field:
- Expires gives the cookie a time constraint. The cookie will only be sent to the server if it is not expired.
- Path Field :
- The cookie path field specifies for which requests, within that domain, the browser send cookie.For cookies with path = /downloads/ , all subsequent requests to:
- /downloads
- /downloads/foo
- /downloads/foo/bar , will include this cookie.
- The browser will not sent this cookie for requests to /blog or /members
- The cookie path field specifies for which requests, within that domain, the browser send cookie.For cookies with path = /downloads/ , all subsequent requests to:
- Content Field :
- A cookie can carry a number of values at once. A server can set multiple values with a single Set-Cookie header by specifying multiple KEY=Value pairs. For example :
Set-Cookie: Username="john"; Authenticated="1"
- A cookie can carry a number of values at once. A server can set multiple values with a single Set-Cookie header by specifying multiple KEY=Value pairs. For example :
- HttpOnly Flag:
- The HttpOnly flag is used to force the browser to send the cookie only through HTTP.
- This flag prevents the cookie from being read via javascript. This is a protection mechanism against cookie stealing via XSS.
-
Secure Flag:
- The Secure flag forces the browser to send the cookie only through HTTPS (SSL).
- This prevents the cookie from being sent in the clear.
-
Here is some correct cookie installation
- Example 1 :
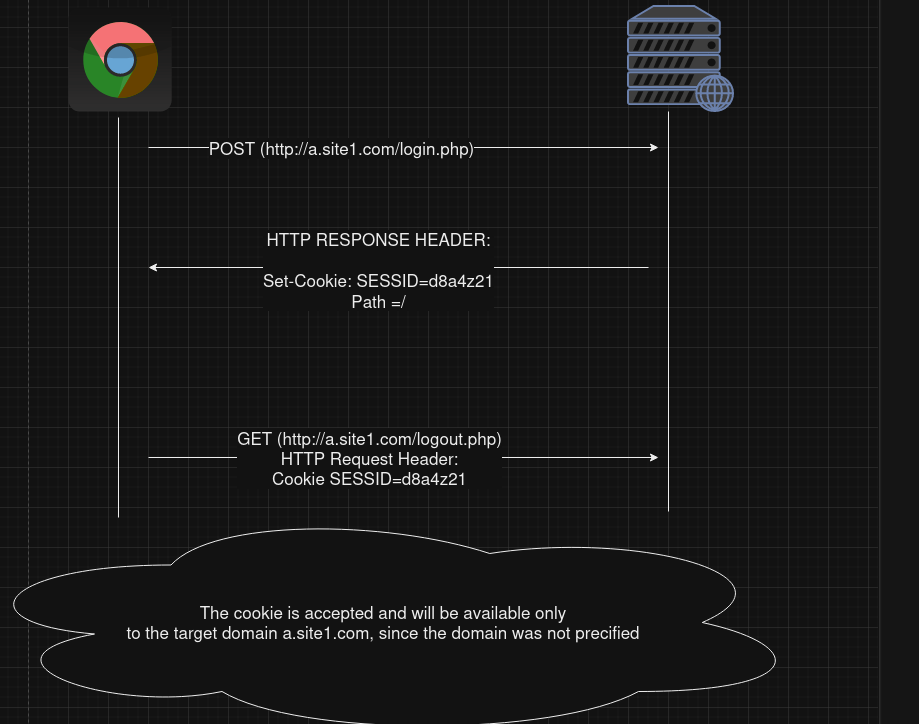
-
This cookie will be sent to each HTTP request matching the following URLs : http://a.site1.com/, https://a.site1.com/
-
Example 2 :
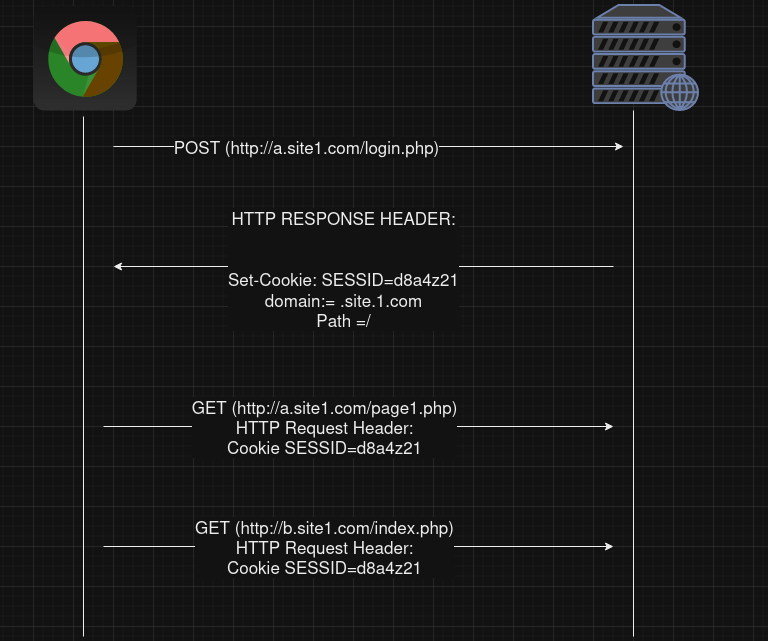
- The cookie accepted because the domain value .site1.com is a suffix of the domain emitting the cookie, a.site1.com , therefor it will be accepted and sent in each request matching the following URLs:
- http://site1.com/*
- https://site1.com/*
- http://.site1.com/
- https://.site1.com/
Session
- Sometimes the web developers prefers to store information on the server side instead of client side.
- This happens in order to hide the application logic or just to avoid the back and forth data transmission, which is typically behavior of cookies.
- HTTP sessions are a simple mechanism that allows websites to store variables spesific for a given visit on the server side.
- Each user session is identified by a either a session id or token , which the server assign to the clients.
- The main difference between cookies and session variable is that cookies are stored on the client side whereas session variables are on the server.
- Also session variables expire with the session and sessions usualy expire sooner than cookies do.
- The session mechanism works through the use of a session token (or session ID).
- The session ID is assigned to the client by the webserver and the client will present this ID for each subsequent request in order to be recognized.
- The session ID provided by the client will let the server retrieve both the state of the client and all of its associated variables.
- Session IDs can be stored within text files, databases or memory on the server.
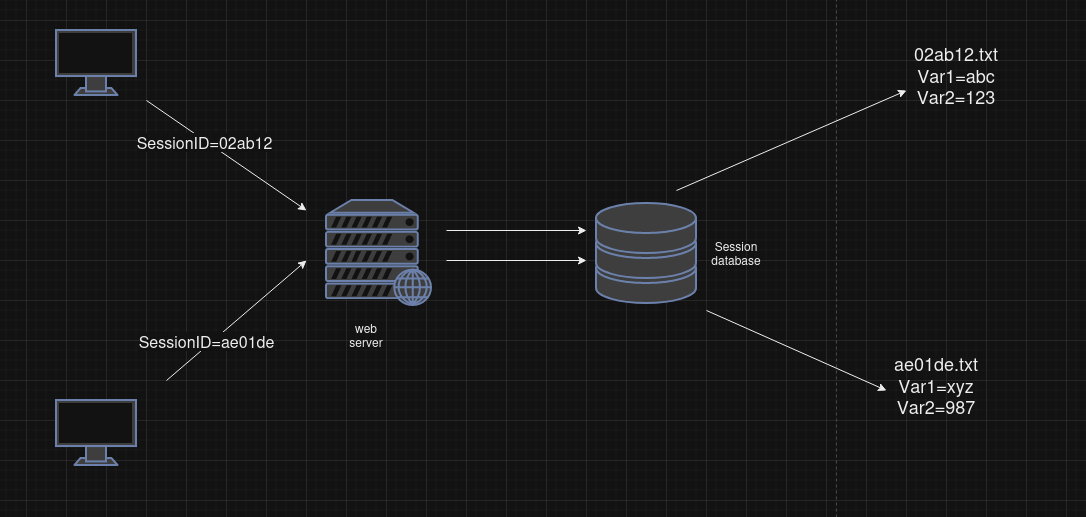
-
Session cookies just contain a single parameter formatted in a key value pair. See the example like below:
- SESSION=0wvCT0BWDH8w
- PHPSESSID=13Kn5Z6Uo4pH
- JSESSIONID=W7DPUBgh7kTM
-
websites running PHP, typically install session cookies by using “PHPSESSID” parameter name, while JSP websites typically use “JSESSIONID”. Each development language has its own default session parameter name and typically allow for developers to customize its functionality.
-
If needed , servers install session cookies after a browser performs some type of activity , such as;
- Opening a specific page
- Changing settings in the web application
- logging in
- Then the browser uses the cookie in subsequent reqıests.
- A session could contain many variables, so sending a small cookie keeps the bandwith usage low.
- In the following example we can see a session cookie in action
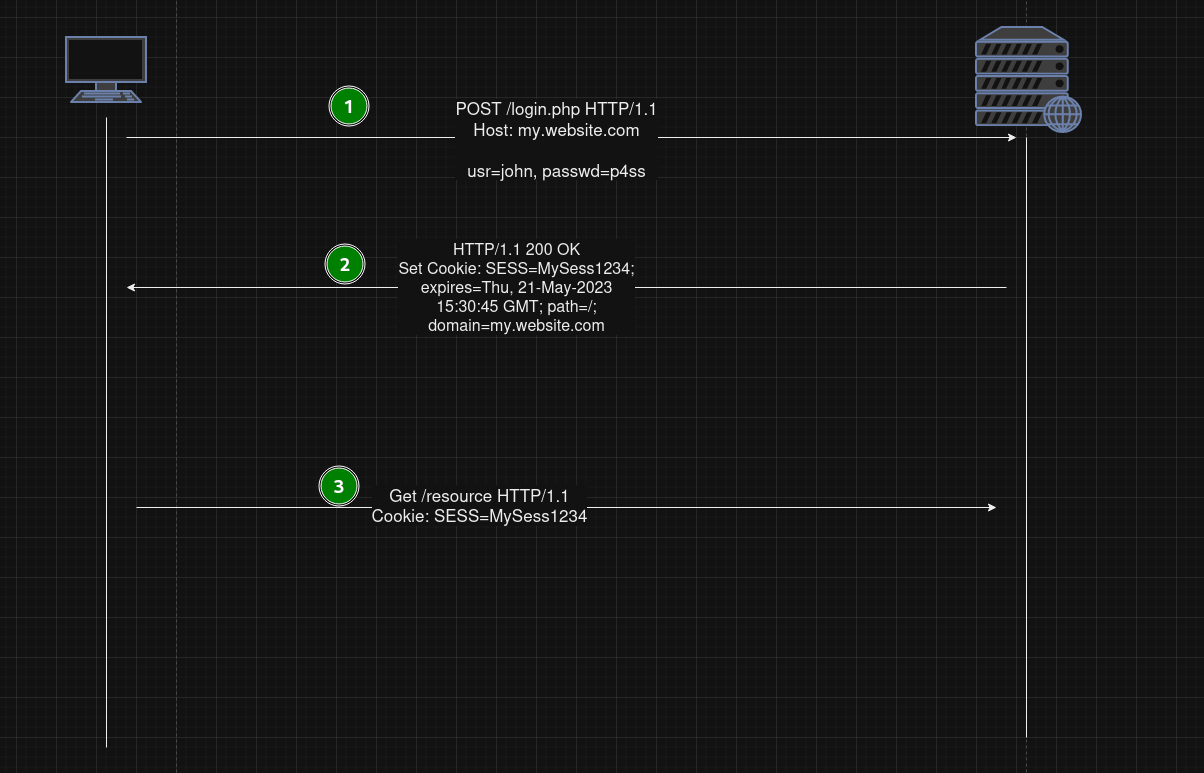
- The client uses a login form to POST the user’s cridentials.
- The server sends back a response with a Set-cookie header field. The cookie contains the session ID
- The browser will send back the cookie according to the cookie protocol, thus sending the session ID.
- Since the web browser has a cookie in its jar, any subsequent request will carry the (session) cookie with it.
- As an alternative to session cookies, session ID’s can also be sent via GET method append to the requesting URL

Web Application Proxies
- Burp Suite
- Owasp Zap